As with many emerging technologies, AI raises interesting and often deeply unsettling fundamental ethical, moral, social, political and privacy issues. However, some questions touch on more practical issues relating to patentability
Artificial intelligence (AI) is now encroaching on many aspects of our lives and will be – according to Google’s CEO Sundar Pichai – more transformative than fire or electricity. Regardless of whether this characterisation will be borne out, AI is considered of such importance to both Microsoft and Google that both are reported to have undergone major reorganisations to bring it to the forefront of their organisations in March and April of this year, respectively.
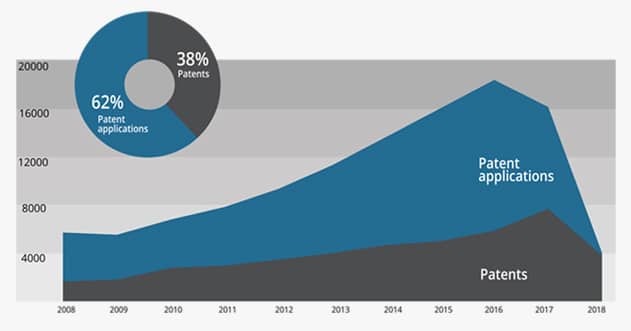
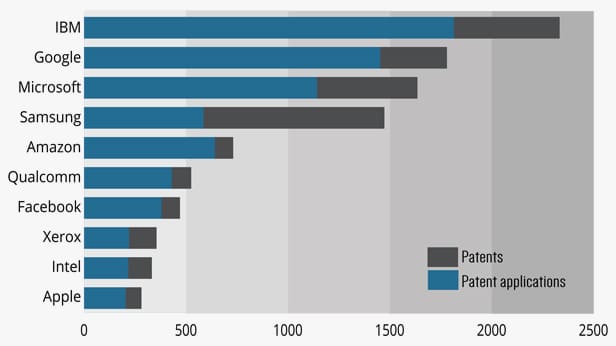
As shown in Figure 1, the number of AI-related US patents and patent application filings has risen substantially since 2008 from only a few patents in the late 1970s, which included a sewing machine with a learning mode and an automated speech recognition system. Figure 2 shows the approximate number of US patents granted and patent applications filed during the last five years assigned to each of the listed 10 companies, which are among the most recognisable and dominant in the AI field.
Although AI – particularly machine learning and its sub-field deep learning – is now being used for a broad spectrum of applications, a dilemma is beginning to emerge that is rooted in our still-limited understanding of how it works. One of the major technical issues facing deep learning has to do with its black-box character.
Despite reassurances from several AI camps that we now have the tools necessary to decode the one or more mechanisms that underpin how AI does what it does, many organisations have recently voiced their concerns about this black-box dilemma. In fact, some of the criticisms levelled at what we refer to here as ‘black-box AI’ have been quite pointed.
In an AI conference last December 2017, Ali Rahimi – a Google AI researcher and winner of the Test-of-Time Award at the 2017 Conference on Neural Information Processing – asserted that machine-learning algorithms have been transmuted into some kind of alchemy. Accordingly, AI researchers understand very little of why certain algorithms work but others do not. In addition, the absence of a reliable and rigorous standard for choosing one AI platform over another poses a serious concern. “There’s an anguish in the field,” Rahimi admitted. “Many of us feel like we’re operating on an alien technology.” In view of these concerns, Rahimi and his cohorts presented several suggestions towards addressing the black-box issue in a paper presented at a subsequent AI conference in Canada, held in April 2018.
Yann LeCun – Facebook’s chief AI scientist in New York City – countered that spending time to investigate how AI works sooner rather than later would detract from the development of cutting-edge AI techniques.
However, releasing an extremely powerful tool for everyone to use without understanding how it works or without implementing safeguards would seem tantamount to courting disaster. We have seen this happen before in the case of the private and public sharing of hacking tools by both white (ethical) and black (malicious) hat hackers. The number of potentially detrimental AI capabilities could likewise increase without checks if we fail to establish the knowledge and tools necessary to prevent or recover from any potential harm that might be caused by black-box AI.
In addition to the argument that it is better to do something about a potentially disastrous situation while we still can, rather than pause to think about it only when irreversible damage has already been inflicted, is the fact that many scientific advances would not have been possible without knowledge derived from both fundamental and applied research. Thus, allotting resources for both fundamental and applied AI research will likely benefit everyone in the long run.
To pre-empt any potential damage relating to AI’s black-box nature, an organisation called the AI Now Institute has recommended that the US government and other agencies that deal with criminal justice, healthcare, welfare and education desist from using AI-based technologies. Several organisations – including the US Department of Defence, Harvard University, Bank of America Corp, Uber Technologies Inc and Capital One Financial Corp – are also trying to address the same issue, as well as the problem of bias involving advanced AI algorithms.

Reproducibility
As well as the black-box conundrum, there is also the issue of reproducibility. This occurs when researchers fail to replicate results generated by other researchers or research groups. While this problem can arise because of the lack of uniformity among AI research protocols and publication practices, there are also fears that the two issues may be linked.
A failure to understand how AI arrives at its decisions during the intermediate and final steps of a learning process could well be the root cause of inconsistent results generated by various AI researchers. In addition, there are other variables that could contribute to this issue, including variations in the following:
- Algorithms used by different researchers;
- The size, source and quality of training data used;
- The installed version of the CPU/GPU/ASIC firmware; and
- The type or architecture of CPU/GPU/ASIC used to run an algorithm.
Bug or feature?
Some contend that AI’s black-box character is not a real issue at all. Science as a whole has been faced with exactly the same interpretability issue for as long as we can remember. Yet, science – despite its shortcomings and failures and despite being constantly hounded by reproducibility issues in many research fields – continues to thrive and is now advancing at a faster rate than ever before.
Physicians, for example, have been providing diagnoses for millions of patients involving all sorts of diseases based on much more limited data than that fed to neural networks. No one has ever presented any conclusive evidence to show that more patients are dying from misdiagnosis compared to those whose health and lives have been improved as a result of treatment based on their physician’s expert opinion. However, this is a very different matter to having swarms of complex, non-ethical and amoral systems spread across the globe that are capable of simultaneously and immediately inflicting potentially serious harm to hundreds of thousands if not millions of people.
For this reason AI researchers should always question whether the AI systems that they are creating will at least solve more problems than they generate.
One possible solution might be to implement an equivalent of the drug approval process through clinical trials. Requiring AI systems to undergo initial testing using a progressively increasing number of test systems or scenarios might be an effective way to uncover lurking flaws that could cause an AI system to behave unpredictably with potentially disastrous consequences.
Black-box AI and abstract ideas
If one is dealing with a black-box AI, one can argue that it should not be considered patentable. According to one of the definitions provided by the *Merriam-Webster Dictionary*, ‘abstract’ means “difficult to understand.”
However, when a deep-learning algorithm is characterised as a black box, it usually means that no one understands how it arrives at the decisions it uses during the processing of an input to generate an output. Based on these definitions of the terms ‘abstract’ and ‘black box’, a black-box AI would be considered an abstract thing. Yet according to US patent law, an abstract thing is not patentable.
In fact, an AI with inner workings that are not well understood, is much more conclusively an abstract thing compared to some business method patent claims that have been adjudicated by the courts to be directed towards patent-ineligible abstract ideas. The reason for this is that when AI researchers characterise a deep-learning algorithm as a black box, there is typically no disagreement that the AI’s black-box component is not well understood. In its present stage of development, it is probably correct to say that an AI is either not well understood or it is. All that is needed is for someone to provide conclusive proof that there is no mystery at all as to how it works.
On the other hand, a compelling counter-argument to the non-patentability of a black-box AI is that patents have been granted for many inventions whose inner workings are only poorly understood, if at all. For example, many patented drugs’ mechanisms-of-action are discovered only after the patents have issued. The fact is, provided that a claimed invention satisfies the patentability criteria pertaining at least to utility, novelty, non-obviousness, written description and enablement, the patent application claims
stand a chance of being allowed.
Unfortunately, the meaning of the term ‘abstract idea’ as used in the patent field has itself become something of a black box. The courts do not appear to have spent much time dwelling on its precise meaning nor have they provided a definition that could meaningfully guide patent practitioners. The more recent definition or interpretation of the term appears to have been more a device of convenience that has merely forced any existing hints about its meaning deeper into a rabbit hole – although it should be stated that trying to come up with a more precise and useful meaning of the term is no trivial task and could inadvertently create more problems than it solves.
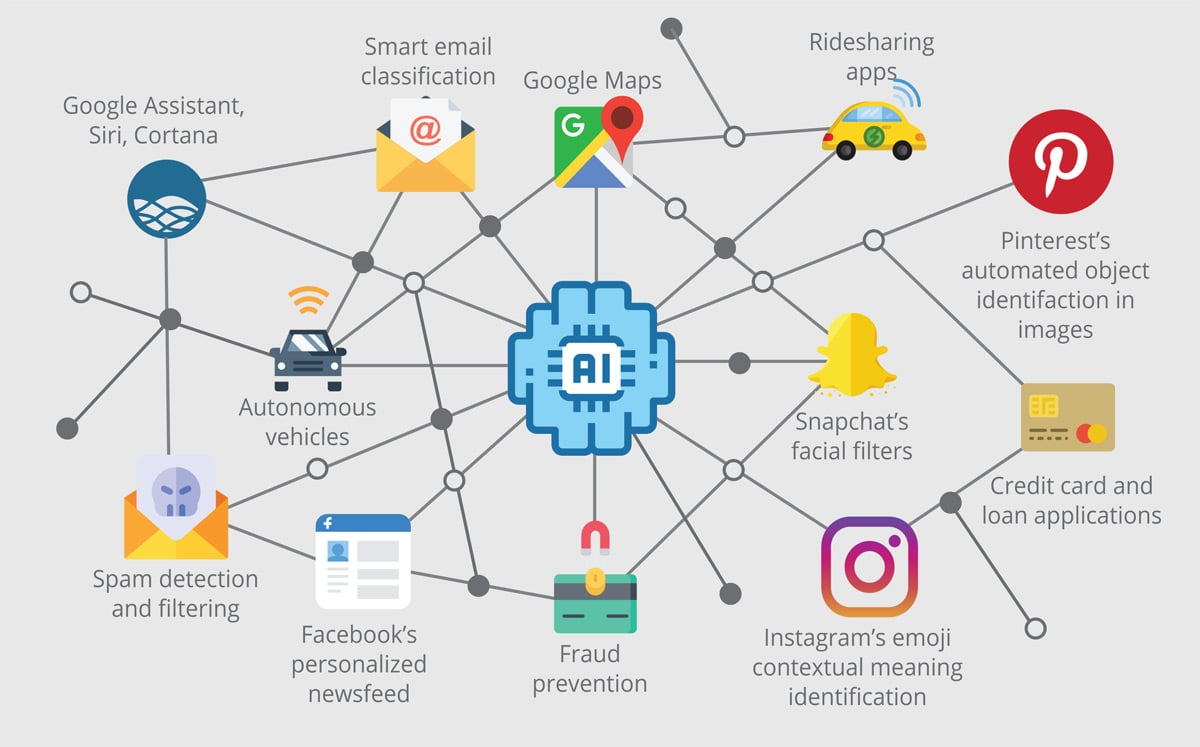
Inventorship
AI is now being used to analyse vast amounts of information from scientific journals, newspapers, magazines, Twitter and Reddit posts, Facebook accounts, Snapchat, patents and other references in order to:
- Extract trends, patterns and connections;
- Test hypotheses based on existing data;
- Calculate the statistical probability that a technique will work for a certain application under certain conditions;
- Provide a ranked list of recommendations on how to proceed to the next step of a research or development process; and
- Determine whether a combination of certain components, techniques or steps will produce a product or process that is more reliable, accurate, stable or fast.
Not only has AI been used for many different applications, but it can carry them out at a scale and speed impossible for humans.
However, the ways that AI has been used for those various applications essentially describes the critical steps in the inventive process (or discovery). In many cases, the human participants merely input the relevant questions, any required initial data or information inputs, or else the preliminary instructions regarding what the AI should look for and analyse. Thus, one can argue that in those cases the substantive act of inventing originates mainly, if not exclusively, from the AI itself.
The question then becomes: should an entity (eg, an individual inventor or company) who relies mostly on an AI to come up with an invention be entitled to any resulting patent?
Obviousness
The legal standard used by the courts to determine whether a claimed invention is not patentable based on obviousness is whether a hypothetical person of ordinary skill in the art would have considered the invention obvious as of the effective filing date of the patent application.
If the courts decide that who or what did the inventing does not matter and the only thing that counts is whether the owner was first to file a patent application, how then do we deal with the obviousness criterion when it comes to an AI-invented invention?
When addressing the issue of obviousness as it relates to an AI invention, we can no longer refer to the hypothetical person of ordinary skill in the art as presently defined by patent law. One possibility is that the courts will decide to expand the definition of the hypothetical ‘person’ of ordinary skill in the art to include an AI.
But in that case, we are faced with another dilemma: how do we determine if an invention would have been considered obvious by an AI of ordinary skill in the art? Should an invention by an AI be judged only according to whether a hypothetical AI, rather than a hypothetical human, of ordinary skill in the art would have considered the claimed invention obvious? And what is ‘ordinary skill’ when referring to an AI?
One emerging area is focusing on how an AI arrives at a decision, given several possible options or scenarios. Because we do not yet know the limits of an AI’s capabilities, if they exist at all, and because the field itself will likely keep evolving for many years to come, we will probably have to wait before we can answer the question regarding what is obvious to a hypothetical AI of ordinary skill in the art.
However, if a certain functionality or capability has already been developed to maturity, perhaps we could reasonably assert by then that the ability of an AI to, say, distinguish a coyote from a jackal would have been obvious to an AI of ordinary skill in the art as of the effective filing date of a patent application. In that case, an examiner might be within the bounds of USPTO rules when rejecting a claim based on obviousness by asserting that it would have been no stretch of the AI’s “imagination” and would thus be a routine matter to apply an AI’s well-documented feline identification skills to other animal genus or species.
Utility and possession of the invention
Let us assume that the algorithm described in the patent application is generally acknowledged by practitioners in the field to be substantially a black-box AI, which generates unpredictable or inconsistent outputs owing to its sensitivity to, for example, the quality or amount of certain input data types (eg, the labelled examples used in image recognition through deep learning). In this case, one can argue that a patent applicant would not have been in possession of the claimed invention as of the effective filing date of the invention. Otherwise how can one say that a patent applicant is in possession of the claimed invention – or if there is any invention at all – if the output of the claimed invention cannot be predicted with reasonable certainty?
Further, would a patent application be enabling if the claimed AI algorithms are known to produce only unpredictable outcomes? A rationale behind a patent application’s enablement requirement is that any member of the public should be able to practice the invention when the patent term ends. However, if the most the public can expect to get from the patented invention are unpredictable outcomes is that a fair bargain? Also, since algorithms are not necessarily described in a detailed way in patent applications, who is to say that the members of the public who attempt to reproduce the invention would not end up with mostly useless results from the invention as described?
Also, would an AI algorithm that produces only unpredictable or inconsistent outputs satisfy the utility requirement, even if some of the outputs it generates are genuinely useful, although most of the times they are not? One possible, although perhaps snarky, answer is as follows: patent applications directed to gambling machines have been previously granted. AI algorithms that yield unpredictable results are not that much different from slot machines. Therefore, AI algorithms that produce unpredictable results only should also be patentable.
On the other hand, if some of the generated outputs of the claimed invention can be potentially dangerous for certain applications under certain conditions because of their underlying unpredictability, it would seem unwise to reward these by issuing patents for them.
AI and availability of data
The other side of the equation that people do not talk about as much is data. The fact is, algorithms such as those used in neural networks require lots of training data before they can become useful for accomplishing certain types of narrowly defined tasks. For real-world applications (eg, drug discovery) one needs lots of data much more sophisticated than the highest resolution images of all the known cat species in the world.
Thus, one might be in possession of the most advanced deep-learning algorithms in the world, but without access to large amounts of high-quality data needed for drug discovery training (eg, data relating to structure-function relationships, results from animal models, x-ray diffraction data and human clinical trials), the output of the neural network algorithm would most likely be unreliable, if not unusable. Garbage in, garbage out.
The problem is while there are huge amounts of chemical, biological and physical data from published scientific journals, the most important data is that which is most relevant to the specific drug or class of drugs covered by the drug discovery study. Unfortunately, this critical data is not usually publicly accessible. According to IBM’s CEO Ginny Rommety, only 20% of the world’s data is searchable, while the rest is in the hands of established businesses.
So, AI-based inventions that require huge amounts of data to be useful will likely matter only in terms of real-world utility and reliability to those who are already in possession of the required data. Given this, there will probably be very few potential licensees for those patented inventions and these will likely be large companies. In this case, the public, or even the companies themselves who file the patent applications, would probably not benefit much from patents granted for those types of inventions.
Patent AI or keep as trade secret?
One important question is when would it make sense to protect AI-based inventions as trade secrets, rather than via patents? If a company has been developing, for example, its own neural network algorithms for its drug-discovery studies, it might be better off protecting any inventions or discoveries it generates relating to the drug-discovery studies as trade secrets, including the neural network algorithms that otherwise might be patentable.
A potential downside to having an invention published through patents or published patent applications is that the disclosure in the patent could help a patentee’s competitors progress more quickly with their own drug-discovery efforts for a competing drug or class of drugs. Also, if a patentee grants a licence to its competitors for the use of its patented neural network algorithms, the competitor could use the patented invention as a basis for creating and perfecting its own neural network algorithms, which could end up being far more sophisticated than those covered by the patent.
Keeping a neural network algorithm a trade secret has its benefits. For one thing it can be used exclusively for far longer than would be possible if it was patented. Also, it may be relatively easy to keep it a trade secret because many of the improvements on the algorithm could be highly dependent on the type, source, amount and quality of data, all of which are exclusively available to the company that developed the patentable algorithm.
| Action Plan |
|---|
| In developing an AI IP protection strategy there are some key points to bear in mind: |
“This article first appeared in IAM Issue 92, published by Globe Business Media Group – IP Division. To view the issue in full, please go to www.iam-media.xn--com-9o0a