Facebook was recently granted the patent for an online system (e.g., social networking system) that allows searching and regulating trademark violations. The online system can receive proofs of trademark registration from trademark owners before proceeding to search and rank contents within the system that are possibly violating those registered trademarks through the support of machine learning. The system can then proceed to control the distribution of those contents (e.g., by blocking or blacklisting content providers) if there are any indications of trademark violations in them.
The granted patent seeks to address a facet of the ever growing issue of intellectual property (IP) rights protection that came along with the rise of social media over the last two decades or so. The overall expansion of social media in the internet allowed users to create and publicly post virtually any content on their personal pages and in various other places in social media platforms to share to others. This freedom provided to users, however, has led to a great issue where widespread infringement on IP rights can easily be done intentionally or even inadvertently by some. Some of the infringing entities in this case may even stand to gain financial benefit in the process if no content regulation is put in place.
Intellectual property owners, particularly companies and other large entities, who have registered and invested on their IPs would evidently want to protect their products and services from various instances of IP right violations, such as counterfeiting, misrepresentation, and other cases of misuse or infringement on the internet. With the ever expanding user base of online social media platforms, however, regulation of the millions of content posted daily on them has only grown more cumbersome and inefficient without relying on some form of automated system fit for doing the task. Presented with this issue, Facebook decided to tap on machine learning techniques to provide them aid in recognizing possible IP right violations, particularly trademark violations, on their site.
Machine learning has definitely improved leaps and bounds over the last two decades at least, and it continues to do so with the greater compute capability, newer techniques and algorithms, and bigger sets of data available for use in various industries. The patent thus envisions the use of a trained machine learning model to predict the likelihood that a content item is violating some registered trademark in their system. The model is designed to output scores based on various features (e.g., account history, keywords, expressions, image features, etc.) extracted from the contents, which may then be weighted and used when ranking them as potential items of interest when presented to the trademark owners.
Besides interactions with the contents on the site, the system may even track interactions with third-party websites that were deemed responsive to the viewing of the content items on the site to provide more information in ranking them. Content items whose scores are below some set threshold value by the owner may also be skipped when reviewing or ranking them to be more efficient. The model can also be periodically retrained using known sets of authentic and fraudulent accounts that are continually updated to maintain the accuracy of the model.
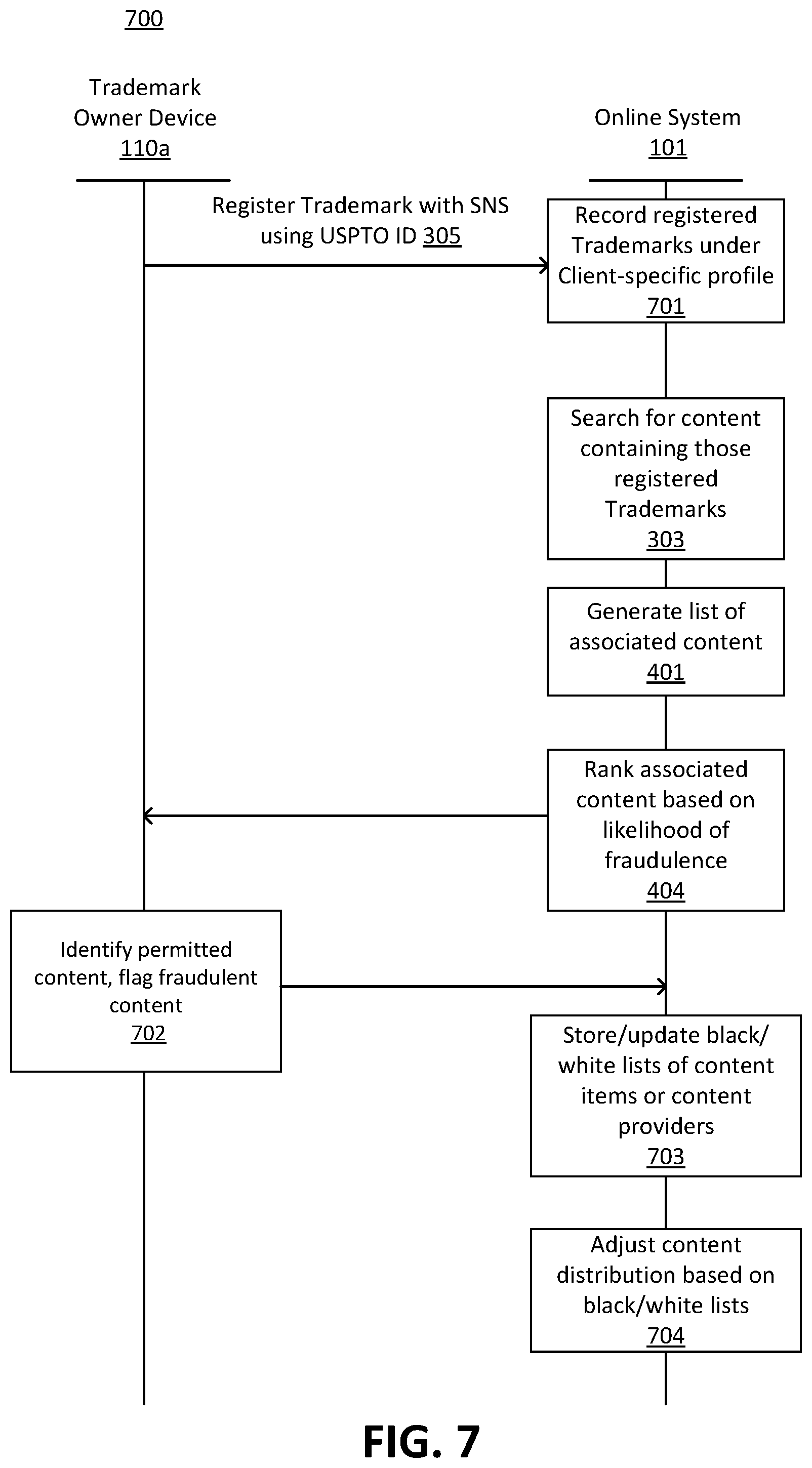
The patented online system essentially offers trademark owners the ability to request a search of possible trademark violations of their IP within the online system, provided with the required trademark registration information and corresponding search parameters (e.g. keywords). The system preliminarily analyzes whether the trademark search is valid, and if there are no other issues with the request, it would then proceed with the search, scoring, ranking, and presentation of the items of interest to the requesting trademark owner.
The system is designed to require the verification of the trademark owner using a proof of the trademark’s registration, which is provided through the certification issued by the United States Patent Trademark Office (USPTO). This can be done either manually or through the online system making application program interface (API) calls to the USPTO website. If verification is unsuccessful, the user may be denied from performing those particular searches to avoid possible misuse of the system. Otherwise, the trademark owner can proceed to review the generated list, choose to blacklist/whitelist content, and basically flag any content they deem to be violating their trademark from the list. Their actions would then be sent back to the online system for possible regulation or adjustment in the distribution of the flagged contents, which would update the information in the online system and allow the system to proceed with any action deemed appropriate against the flagged contents, consistent with the system’s own policies and agreements.
The use of machine learning in the development of this online system is certainly a viable step towards implementing more effective and sustainable systems in protecting IP rights on the internet. However, as with the case with any new automated systems, it would be of eventual great interest to see where the patented system may still need possible improvements or changes in the future as the dynamics between the users, IP, and the internet landscape adapt to its prolonged deployment and continual use in social media.
The featured top patent, “Searching for trademark violations in content items distributed by an online system”, published as U.S. Patent No. 11,004,164, was filed on October 27, 2017 to the U.S. Patent and Trademark Office with application number 15/796,659. The inventors of the granted patent are Sean M. Lantz, Zackary Daniel Darwin, Ulziibayar Otgonbaatar, Michal Zgliczynski, Willy Huang, and Eric Tauseng Wei. The patent is currently assigned to Facebook, Inc.